员工流失预测简介
员工流失(或离职)是全球组织面临的重要问题。了解和预测哪些员工可能离职可以帮助公司实施保留策略,减少招聘和培训新员工的成本。
员工流失率(AR)计算公式为:
\[AR = \frac{\text{在期X内离职的员工数}}{\text{期X内的员工总数}} \times 100\]R中的数据准备
在进行分析之前,让我们先了解如何在R中准备数据。R中的一个重要概念是因子(factor)数据类型,用于表示分类变量。因子对我们的分析至关重要,因为它们:
- 以整数形式存储类别,提高效率
- 保持标签,便于人类阅读
- 在统计模型中自动转换为虚拟变量
因子内部以整数形式存储类别(相对于字符串更高效),并附加标签。这些值可以是有序的或无序的。我们称这些唯一值为因子水平。在统计建模中,像lm()、glm()和randomForest()这样的函数会将因子视为分类变量,并自动创建虚拟变量。
x <- c("low", "medium", "high", "low", "high")
f <- factor(x)
print(f)
# [1] low medium high low high
# Levels: high low medium
让我们看看这段代码,它在数据框df中创建了一个名为leave的二元因子变量。我们将使用df$leave作为分类任务中的因变量(标签)。
df$leave <- factor(ifelse(df$Attrition == "Yes", "Yes", "No"), levels = c("No", "Yes"))
- df$Attrition == “Yes” 对每一行返回一个逻辑向量(TRUE或FALSE)
- ifelse(…, “Yes”, “No”) 将逻辑向量转换为字符向量(TRUE转换为”Yes”)
- factor(…, levels=c(“No”, “Yes”)) 将结果字符向量转换为具有两个水平的因子:”No”和”Yes”。这里的顺序很重要,因为许多分类模型默认将最后一个水平(”Yes”)视为正类
- 最后df$leave <- 将生成的因子赋值给数据框df中的新列leave
这段代码确保我们为分类任务准备了一个正确的因子标签。这是像glm和randomForest这样的R模型所必需的。我们还可以通过控制因子水平的顺序使建模更加明确和稳定。
数据探索和可视化
在构建预测模型之前,让我们先探索和可视化数据,以了解变量之间的模式和关系。
summary(df[, c("Age", "MonthlyIncome", "EnvironmentSatisfaction", "JobSatisfaction")])
- df[, c(…)] 从数据框df中选择一列子集
- summary(…) 然后为每个选定的列提供统计信息
- 对于数值变量(Age, MonthlyIncome),它显示以下内容:
Min. 1st Qu. Median Mean 3rd Qu. Max.
其中:
- Min.: 最小值
- 1st Qu.: 第一四分位数(25%分位数)
- Median: 中位数(50%分位数)
- Mean: 平均值
- 3rd Qu.: 第三四分位数(75%分位数)
- Max.: 最大值
- 对于分类变量或整数编码的分类变量(JobSatisfaction (1-4)),它显示每个水平的计数。
1 2 3 4
100 150 120 130
数据可视化
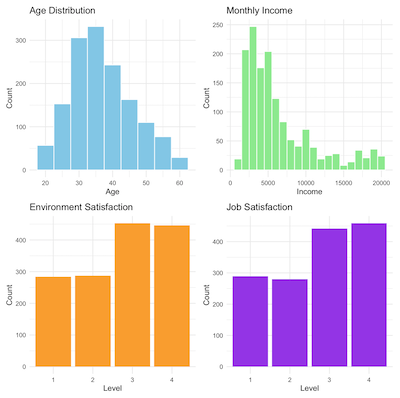
我们使用ggplot2进行绘图。
ggplot(data = df, aes(x = Attrition, fill = Attrition))
- ggplot(…) 使用df(数据框)作为数据创建ggplot对象
- aes: 美学映射,它告诉哪些变量从您的数据映射到图的美学属性
- x, y: 轴上的位置
- fill: 条形或区域颜色
- color: 线或点的颜色
- size: 点/线的大小
- shape: 点的形状
- alpha: 透明度
ggplot(df, aes(x = Age)) +
geom_histogram(binwidth = 5, fill = "skyblue", color = "white") +
labs(title = "年龄分布", x = "年龄", y = "人数") +
theme_minimal()
- 我们将年龄设置为x轴
- geom_histogram(…): 添加一个直方图层,其中
- binwidth表示每个条形(bin)覆盖5年的范围
- fill使条形呈现天蓝色
- color使条形边框为白色
- labs(…) 添加图的标签:
- title = “年龄分布”,这是图的标题
- x = “年龄” 是x轴的标签
- y = “人数” 是y轴的标签
- theme_minimal() 为图应用一个简洁的极简主题。它使用浅色背景,没有网格线,使用简单的字体和布局
如果我们绘制四个单独的图并将它们放在一起,我们就会得到上面显示的图:
# 如果需要安装包
install.packages("ggplot2")
install.packages("patchwork")
# 加载库
library(ggplot2)
library(patchwork)
# 将满意度评分转换为因子
df$EnvironmentSatisfaction <- factor(df$EnvironmentSatisfaction, levels = 1:4)
df$JobSatisfaction <- factor(df$JobSatisfaction, levels = 1:4)
# 创建图表
p1 <- ggplot(df, aes(x = Age)) +
geom_histogram(binwidth = 5, fill = "skyblue", color = "white") +
labs(title = "年龄分布", x = "年龄", y = "人数") +
theme_minimal()
p2 <- ggplot(df, aes(x = MonthlyIncome)) +
geom_histogram(binwidth = 1000, fill = "lightgreen", color = "white") +
labs(title = "月收入", x = "收入", y = "人数") +
theme_minimal()
p3 <- ggplot(df, aes(x = EnvironmentSatisfaction)) +
geom_bar(fill = "orange") +
labs(title = "环境满意度", x = "等级", y = "人数") +
theme_minimal()
p4 <- ggplot(df, aes(x = JobSatisfaction)) +
geom_bar(fill = "purple") +
labs(title = "工作满意度", x = "等级", y = "人数") +
theme_minimal()
# 组合成一个布局
dashboard <- (p1 | p2) / (p3 | p4)
# 保存为PNG
ggsave("dashboard_plot.png", plot = dashboard, width = 10, height = 8, dpi = 300)
# 或者选择保存为PDF
ggsave("dashboard_plot.pdf", plot = dashboard, width = 10, height = 8)
构建预测模型
线性模型
让我们从一个简单的线性回归模型开始,以了解变量与员工流失之间的关系:
# 线性回归(使用数值型leave以保持一致性)
df$leave_numeric <- as.numeric(df$leave) - 1 # 转换为0/1用于回归
mymodel <- lm(leave_numeric ~ Age + MonthlyIncome + EnvironmentSatisfaction + JobSatisfaction,
data = df)
summary(mymodel)
stargazer(mymodel, type = "text")
- df$leave 是一个具有”No”和”Yes”两个水平的因子
- as.numeric(df$leave) 将”No”转换为1,”Yes”转换为2。减去1后分别得到0和1,这使它们适合用于回归
- lm(…) 是线性模型
- lm(leave_numeric ~ …) 表示我们使用…(Age, MonthlyIncome, EnvironmentSatisfaction, 和 JobSatisfaction)来预测leave_numeric
- summary(mymodel) 显示以下字段:
- 每个预测变量的系数
- R平方
- F统计量
- 预测变量显著性的p值
- 解释:每个变量与离职概率的关系(大致)
- stargazer(…) 打印清晰的出版风格摘要。
====================================================
因变量:
---------------------------
leave_numeric
----------------------------------------------------
Age -0.004***
(0.001)
MonthlyIncome -0.00001***
(0.00000)
EnvironmentSatisfaction2 -0.110***
(0.030)
EnvironmentSatisfaction3 -0.121***
(0.027)
EnvironmentSatisfaction4 -0.120***
(0.027)
JobSatisfaction2 -0.062**
(0.030)
JobSatisfaction3 -0.069**
(0.027)
JobSatisfaction4 -0.116***
(0.027)
Constant 0.539***
(0.048)
----------------------------------------------------
Observations 1,470
R2 0.062
Adjusted R2 0.057
Note: *p<0.1; **p<0.05; ***p<0.01
回归树
接下来我们使用公式构建一个回归树。
myformula <- formula(leave ~ Age + MonthlyIncome + EnvironmentSatisfaction + JobSatisfaction)
tree.model <- rpart(myformula, method = "class", data = df)
- 我们已经在线性回归模型示例中看到了公式(隐式公式)。公式表示变量之间的关系。运算符是’~’,左侧是响应变量或结果(因变量)。右侧是预测变量(自变量)。
- 接下来我们使用rpart()函数(递归划分)拟合分类树
- method = “class” 告诉rpart()执行分类(而不是回归)
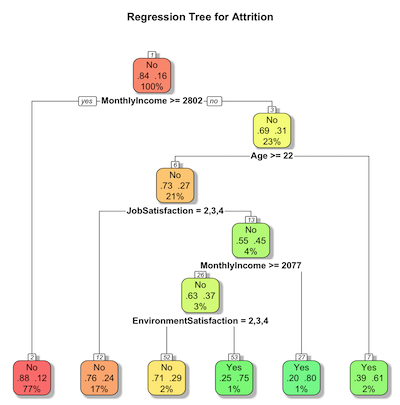
现在我们绘制回归树并保存图形
# 使用rpart.plot可视化回归树
rpart.plot(tree.model,
main="员工流失预测树",
extra=104, # 控制每个节点显示的信息
box.palette="GnBu", # 使用绿色调色板
shadow.col = "gray", # 添加灰色阴影以提高可读性
nn = TRUE) # 显示节点编号
- rpart.plot(tree.model,…) 绘制树模型
- main=”…” 设置图的标题
- extra=104 控制每个节点显示的信息:
- 100 -> 显示类别概率
- 4 -> 显示节点中的观察数量
随机森林
接下来我们进行随机森林(分类,使用有效的mtry):
set.seed(1234)
model.rf <- randomForest(myformula, data = df, ntree = 1000, mtry = 2,
proximity = TRUE, importance = TRUE)
print(model.rf)
varImpPlot(model.rf, main = "变量重要性")
- set.seed(100) 为随机森林的样本抽取和随机特征选择设置种子,使结果稳定
- model.rf <- randomForest(…) 训练随机森林分类器
- ntree = 1000 在森林中构建1000棵决策树(从启发式角度看,更多的树意味着更稳定的结果,但会影响性能)
- mtry = 2 表示在每次分割时随机选择2个变量进行考虑,这对于控制过拟合很有帮助
- proximity = TRUE 计算接近度矩阵,或成对样本落在相同终端节点的频率
- importance = TRUE 存储变量重要性度量
- print(model.rf) 输出拟合模型的摘要,包括:
- 错误率
- 混淆矩阵
- 类别分布
- varImpPlot(…) 绘制变量重要性度量:
- 准确率降低均值:如果这个变量被置换,模型准确率下降了多少
- Gini降低均值:这个变量在减少树的不纯度方面的重要性
或者我们可以将数据分为训练集和测试集:
set.seed(123)
training.samples <- createDataPartition(df$leave, p = 0.7, list = FALSE)
train.data <- df[training.samples, ]
test.data <- df[-training.samples, ]
# 随机森林性能(分类)
model.rf <- randomForest(myformula, data = train.data, ntree = 1000, mtry = 2,
proximity = TRUE, importance = TRUE)
predictions.rf <- predict(model.rf, test.data)
# 将预测转换为数值用于度量
predictions.rf_numeric <- as.numeric(predictions.rf) - 1
metrics.rf <- data.frame(
R2 = R2(predictions.rf_numeric, test.data$leave_numeric),
RMSE = RMSE(predictions.rf_numeric, test.data$leave_numeric),
MAE = MAE(predictions.rf_numeric, test.data$leave_numeric)
)
print("随机森林度量:")
print(metrics.rf)
这就是我们关于R的入门教程。